XML和JSON的使用(java)
XML
概述
XML全称可扩展标记语言(eXtensible Markup Language)。是一种用于标记电子文件使其具有结构性的标记语言。
在电子计算机中,标记指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种的信息比如文章等。它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 它非常适合万维网传输,提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。是Internet环境中跨平台的、依赖于内容的技术,也是当今处理分布式结构信息的有效工具。早在1998年,W3C就发布了XML1.0规范,使用它来简化Internet的文档信息传输。
特性:
- xml具有平台无关性, 是一门独立的标记语言.
- xml具有自我描述性
用途
- 网络数据传输
- 数据存储
- 配置文件
.XML文件是保存XML数据的一种方式,XML数据也可以以其他的方式存在(如在内存中构建XML数据)。不要将XML语言狭隘的理解成XML文件。
###XML语法
基本语法
在XML文档开头,要先写XML文档声明,格式如下:
1 |
XML文档正文都是由一个个的标记组成的,包含:
- 开始标记(开放标记): <标记名称>
- 结束标记(闭合标记): </标记名称>
- 标记内容: 开始标记与结束标记之间 ,是标记的内容。
标记名称: 自定义名称,必须遵循以下命名规则:
- 名称可以含字母、数字以及其他的字符
- 名称不能以数字或者标点符号开始
- 名称不能以字符 “xml”(或者 XML、Xml)开始
- 名称不能包含空格,不能包含冒号(:)
- 名称区分大小写
例如 ,我们通过标记, 描述一个名字:
1 | <name>答案</name> |
注意:
一个XML文档中,必须有且且仅允许有一个根标记。
标记可以嵌套, 但是不允许交。
标记名称 允许重复
标记的层级称呼 (子标记,父标记 ,兄弟标记,后代标记 ,祖先标记),例如下面代码:
1
2
3
4
5
6
7
8
9
10<persons>
<person>
<name>张三</name>
<length>180cm</length>
</person>
<person>
<name>李四</name>
<length>200cm</length>
</person>
</persons>name是person的子标记,是person的后代标记,是persons的后代标记,是length的兄弟标记。person是name的父标记。persons是name的祖先标记。
标记除了开始和结束 , 还可以包含属性。标记中的属性,在标记开始时描述,由属性名和属性值组成。
在开始标记中, 描述属性,可以包含0-n个属性,每一个属性是一个键值对!
属性名不允许重复 ,键与值之间使用等号连接, 多个属性之间使用空格分割,属性值 必须被引号引住。例如:1
2
3
4
5
6<persons>
<person id="10001" groupid="1">
<name>李四</name>
<age>18</age>
</person>
</persons>可以在XML文档中写注释,但是不能写在文档声明前,不能嵌套注释。
格式如下:1
<!-- 注释 -->
语法进阶CDATA
CDATA 是不会被 XML 解析器解析的文本数据。像 “<” 和 “&” 字符在 XML 元素中都是非法的。
“<” 会产生错误,因为解析器会把该字符解释为新元素的开始。
“&” 会产生错误,因为解析器会把该字符解释为字符实体的开始。
某些文本,比如 JavaScript 代码,包含大量 “<” 或 “&” 字符。为了避免错误,可以将脚本代码定义为 CDATA。CDATA 部分中的所有内容都会被解析器忽略。定义格式如下:
1 | <![CDATA[脚本代码]]> |
Java解析XML
在java中,XML可以通过下面四种方式解析
- SAX解析
- DOM解析
- JDOM解析
- DOM4J解析
其实也可以说成SAX和DOM两种解析方式,因为后面两种也属于DOM解析,是由DOM解析的基础上扩展来的,只是用与Java。
SAX解析
解析方式是事件驱动机制 !
SAX解析器,逐行读取XML文件进行解析 ,每当解析到一个标签的开始/结束/内容/属性时,触发事件。我们可以编写程序在这些事件发生时,进行相应的处理。
优点:
- 分析能够立即开始,而不是等待所有的数据被处理
- 逐行加载,节省内存。有助于解析大于系统内存的文档
- 有时不必解析整个文档,它可以在某个条件得到满足时停止解析。
缺点:
- 单向解析,无法定位文档层次,无法同时访问同一文档的不同部分数据(因为逐行解析,当解析第n行时,第n-1行已经被释放了,无法再进行操作了)。
- 无法得知事件发生时元素的层次,只能自己维护节点的父/子关系.
- 只读解析方式,无法修改XML文档的内容。
DOM解析
是用与平台和语言无关的方式表示XML文档的官方W3C标准,分析该结构通常需要加载整个文档和内存中建立文档树模型。程序员可以通过操作文档树,来完成数据的获取、修改、删除等.
优点:
- 文档在内存中加载,允许对数据和结构做出更改.
- 访问是双向的,可以在任何时候在树中双向解析数据。
缺点:
- 文档全部加载在内存中,消耗资源大.
JDOM解析
目的是解析为Java特定文档模型,它简化与XML的交互并且比使用DOM实现更快。由于是第一个Java特定模型,JDOM一直得到大力推广和促进。
优点:
- 使用具体类而不使用接口,简化了DOM的API。
- 大量使用了Java集合类,方便了Java开发人员。
缺点:
- 没有较好的灵活性。
- 性能不是那么优异。
DOM4J解析
它是JDOM的一种智能分支。它合并了许多超出基本XML文档表示的功能,包括集成的XPath支持、XML Schema支持以及用于大文档或流化文档的基于事件的处理。它还提供了构建文档表示的选项。
DOM4J是一个非常优秀的Java XML API,具有性能优异、灵活性好、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的Java软件都在使用DOM4J来读写XML。
DOM4J解析XML
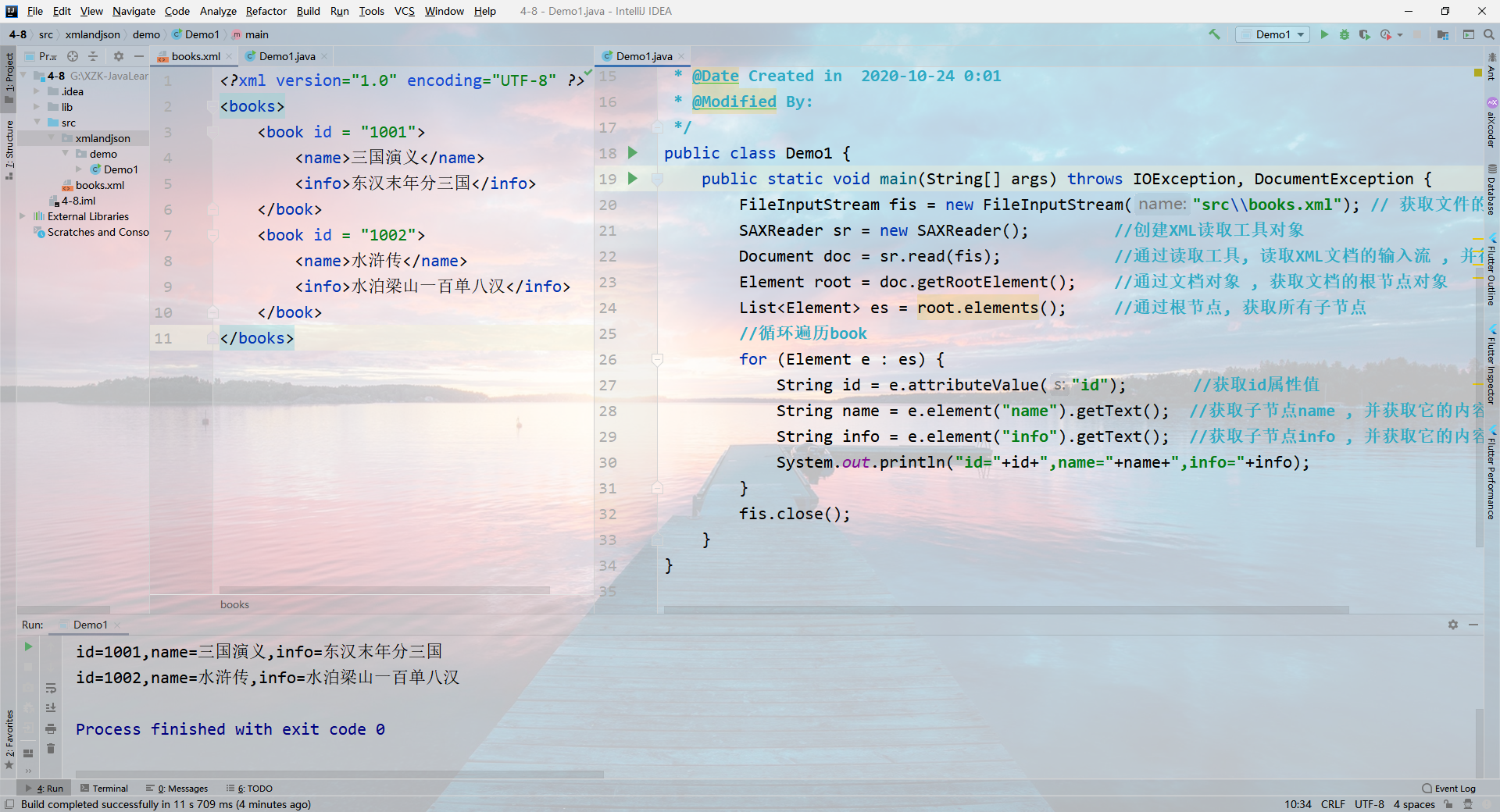
步骤:
引入DOM4j的jar包 dom4j.jar
创建一个指向XML文件的输入流
1
FileInputStream fis = new FileInputStream("xml文件的地址");
创建一个XML读取工具对象
SAXReader1
SAXReader sr = new SAXReader();
使用读取工具对象,读取XML文档的输入流, 并得到文档对象
Document1
Document doc = sr.read(fis);
通过文档对象, 获取XML文档中的根元素对象
Element root1
Element root = doc.getRootElement();
文档对象 Document
指的是加载到内存的 整个XML文档。常用方法:
通过文档对象, 获取XML文档中的根元素对象
1
Element root = doc.getRootElement();
添加根节点
1
Element root = doc.addElement("根节点名称");
元素对象 Element
指的是XML文档中的单个节点。常用方法:
| 方法 | 描述 |
|---|---|
String getName() |
获取当前节点的标记名称 |
String getText() |
获取节点内容 |
void setText(String s) |
设置节点内容 |
String attributeValue(String s) |
获取节点的属性值,s表示属性名称 |
void addAttribute(String key,String value) |
添加属性 (key属性名,value属性值) |
Element element(String name) |
根据子节点名称获取匹配名称的第一个子节点对象 |
List<Element> elements() |
获取所有的子节点对象 |
String elementText(String s) |
返回子节点内容,s表示子标签名称 |
Element addElement(String name) |
添加子节点 (name子节点名称) |
解析本地文件案例
解析网络文件案例

DOM4J - XPATH解析XML
XPATH就是通过路径快速的查找一个或一组元素
| 标记 | 解释 |
|---|---|
| / | 从根节点开找 |
| // | 查找后代节点 |
| . | 查找当前节点 |
| … | 查找父节点 |
| @ | 选择属性,属性使用方式: [@属性名=‘值’] [@属性名>‘值’] [@属性名<‘值’] [@属性名!=‘值’] |
例如:在我们解析本地文件案例中有一个books.xml文件,如果我们想找到 “三国演义”这个元素,XPATH 路径k可以这样写:
1 | //book[@id='1001']//name |
通过Node类的两个方法, 来完成查找(Node是 Document 与 Element 的父接口)
方法1,根据路径表达式, 查找匹配的单个节点,如果结果有多个,只取第一个
1 | Node e = selectSingleNode("路径表达式"); |
方法2,根据路径表达式, 查找匹配的所有节点
1 | List<Node> es = selectNodes("路径表达式"); |
例子:
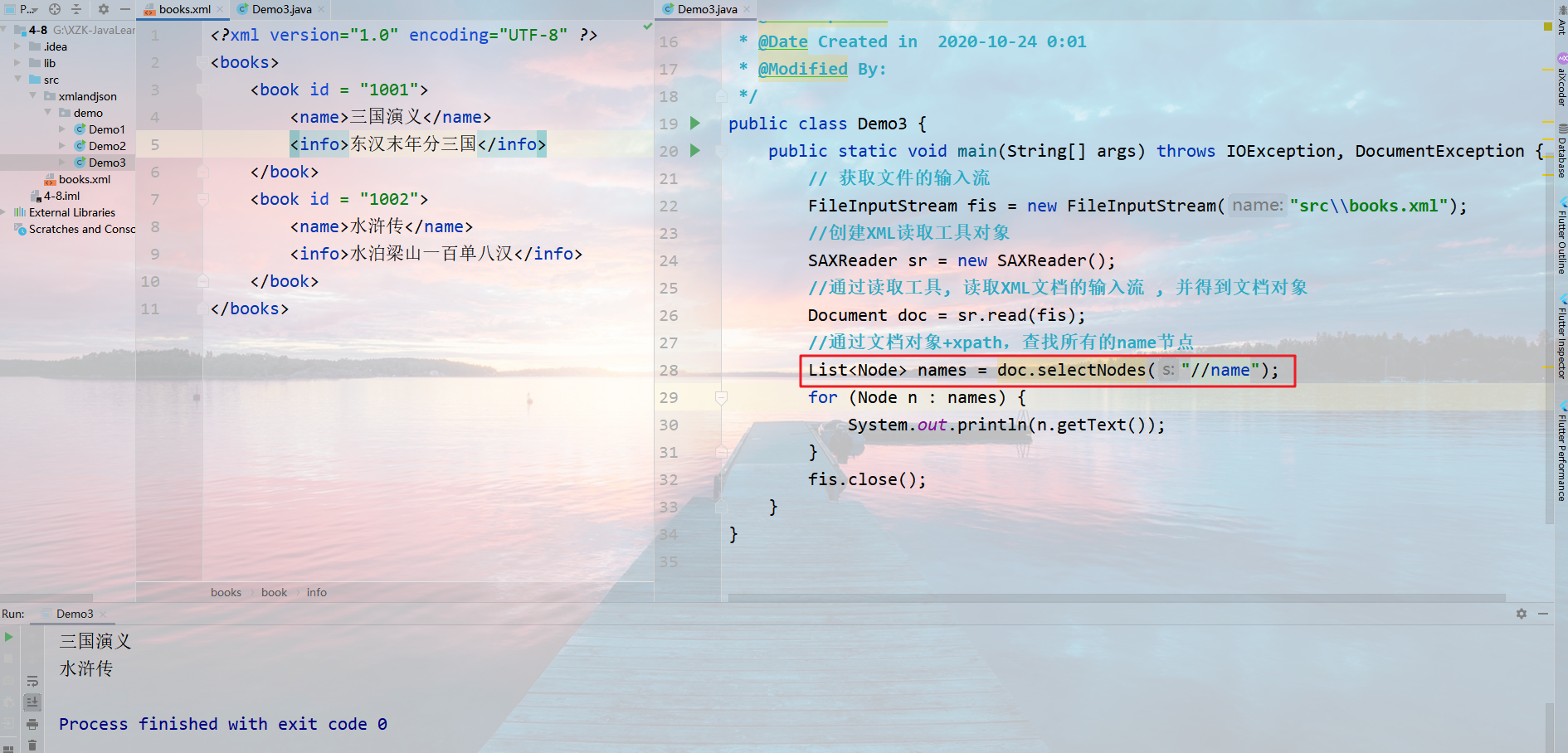

Java生成XML
步骤:
通过文档帮助器 (
DocumentHelper) ,创建空的文档对象1
Document doc = DocumentHelper.createDocument();
通过文档对象,向其中添加根节点
1
Element root = doc.addElement("根节点名称");
通过根节点对象root , 丰富我们的子节点
1
Element e = root.addElement("元素名称");
创建一个文件输出流 ,用于存储XML文件
1
FileOutputStream fos = new FileOutputStream("要存储的位置");
将文件输出流, 转换为XML文档输出流
1
XMLWriter xw = new XMLWriter(fos);
写出文档
1
xw.write(doc);
释放资源
1
xw.close();
例子
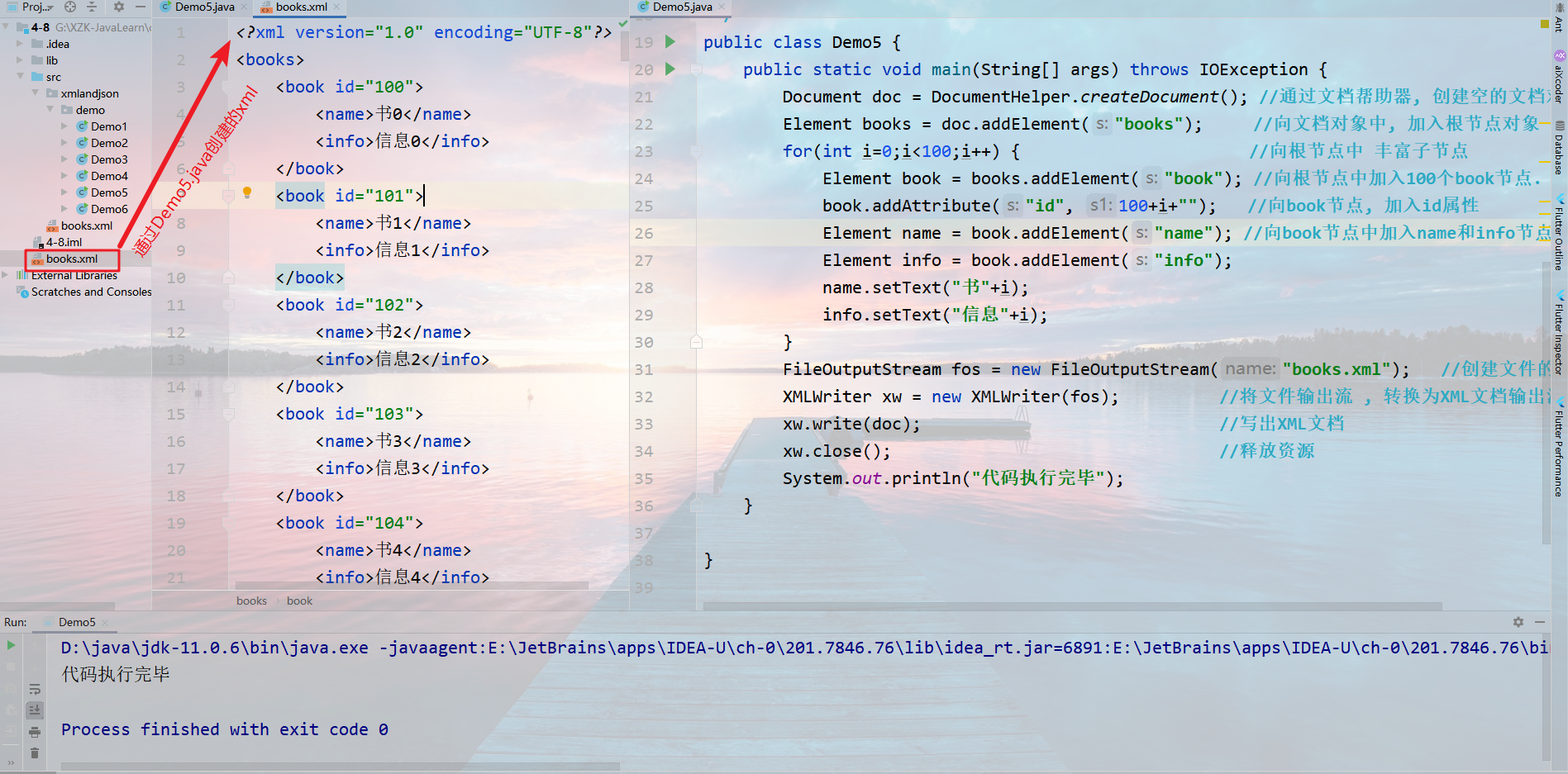
####XStream的使用
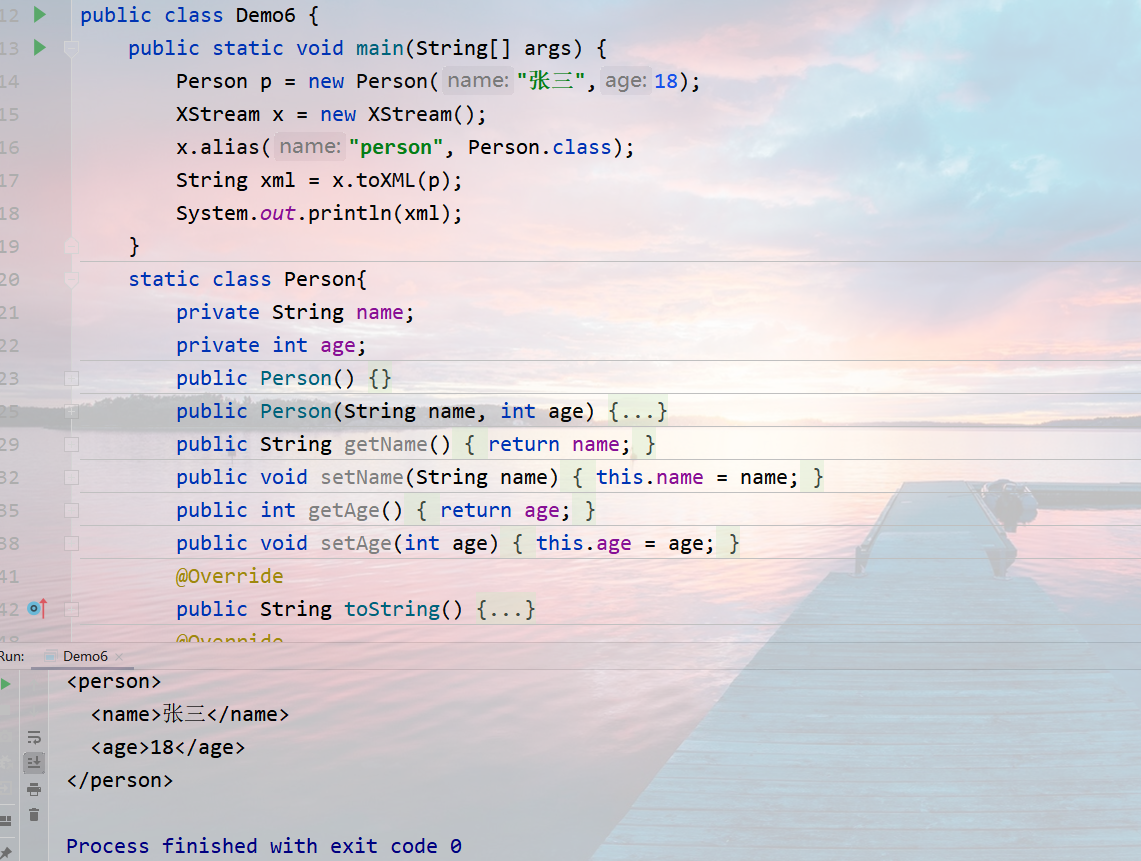
快速的将Java中的对象, 转换为 XML字符串.
使用步骤:
创建XStream 对象
1
XStream x = new XStream();
修改类生成的节点名称 (默认节点名称为 包名.类名)
1
x.alias("节点名称",类名.class);
传入对象 , 生成XML字符串
1
String xml字符串 = x.toXML(对象);
例子:
JSON
概述
JSON全称JavaScript Object Notation ,JS对象简谱 ,是一种轻量级的数据交换格式。
它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
JSON是[Douglas Crockford](https://baike.baidu.com/item/Douglas Crockford/5960317)在2001年开始推广使用的数据格式,在2005年-2006年正式成为主流的数据格式,雅虎和谷歌就在那时候开始广泛地使用JSON格式。
json语法
该部分内容参考自https://www.sojson.com/json/json_syntax.html
版权所属:SOJSON(原创文章)
json 语法规则
- 数据在名称/值对中,也就是我们常说的键值对,用逗号分隔
- 花括号{}保存对象
- 方括号[]保存数组
JSON 数据的书写格式是:{Key:Value}、{Key:Array}。前面是键,中间是英文的“:”(冒号),然后是值。但是注意的是如果是字符串,严格来说都是要用英文双引号引起来的。例如:
1 | {"name":"answer"} |
JSON数据的值可以是 **数字(整数或浮点数)、字符串(在双引号中)、逻辑值(true 或 false)、数组(在方括号中)、对象(在花括号中)、null**。
JSON对象在花括号中,对象可以包含多个名称/值对,如下代码所示:
1 | { |
JSON数组在方括号(”[]”)中书写,数组可包含多个对象,如下“student”描述
1 | { |
在上面的例子中,对象 “student” 是包含三个对象的数组。每个对象代表一条关于一个学生(姓名和年龄)的记录。
Java解析转换JSON
将Java中的对象快速的转换为JSON格式的字符串。
将JSON格式的字符串, 转换为Java的对象。
Java官方未提供官方的json解析工具,json的解析借助第三方工具完成。常见的第三方工具有谷歌的Gson和阿里巴巴的fastjson。在使用前都要先导入jar包,可以从某hub上下载。

Gson
将对象转换为JSON字符串,在需要转换JSON字符串的位置编写如下代码即可:
1 | String json = new Gson().toJSON(要转换的对象); |
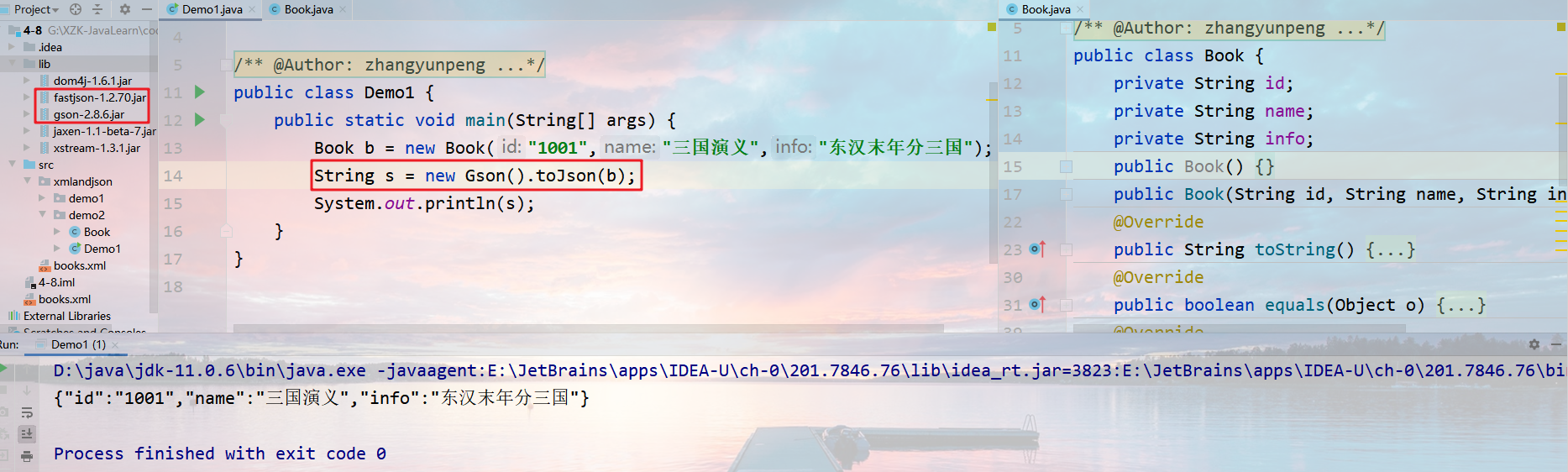
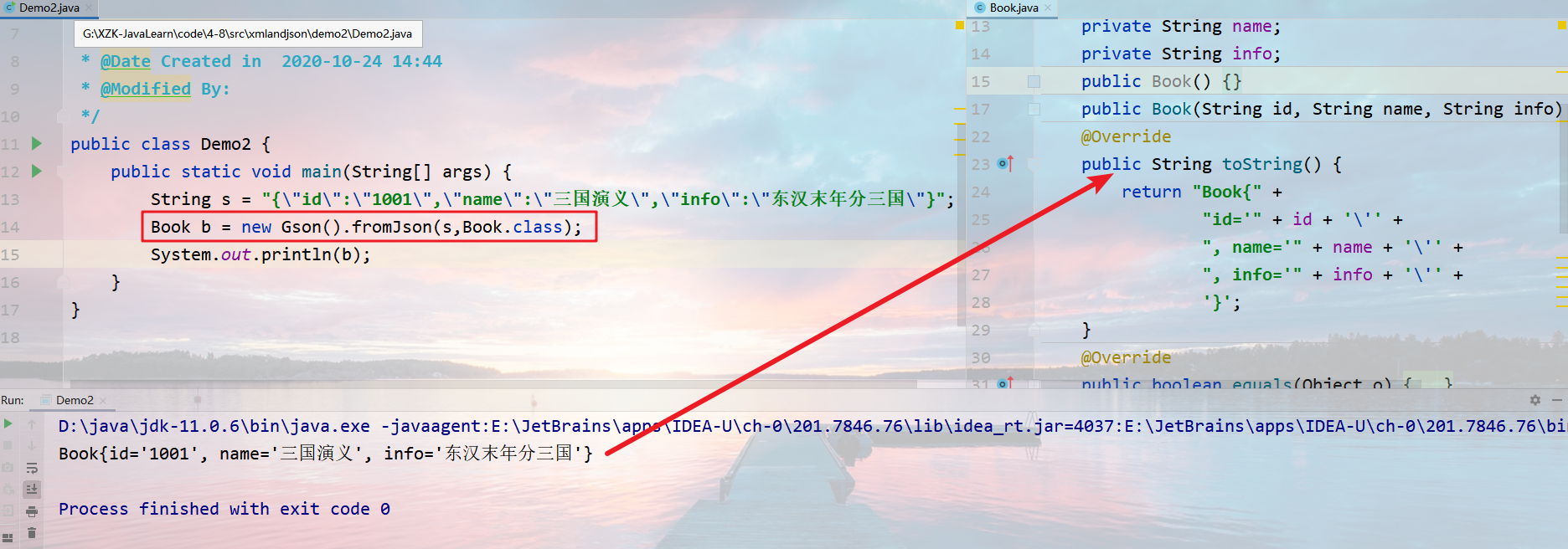
将JSON字符串转换为对象,在需要转换Java对象的位置,编写如下代码:
1 | 对象 = new Gson().fromJson(JSON字符串,对象类型.class); |
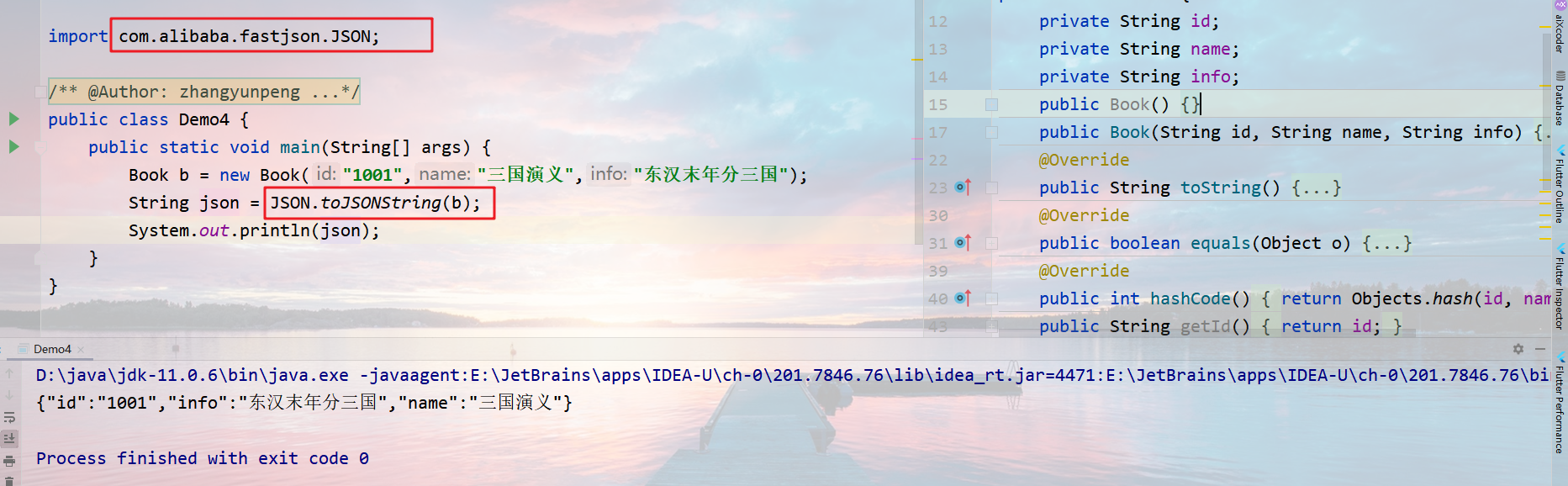
FastJson
将对象转换为JSON字符串,在需要转换JSON字符串的位置编写如下代码即可:
1 | String json=JSON.toJSONString(要转换的对象); |
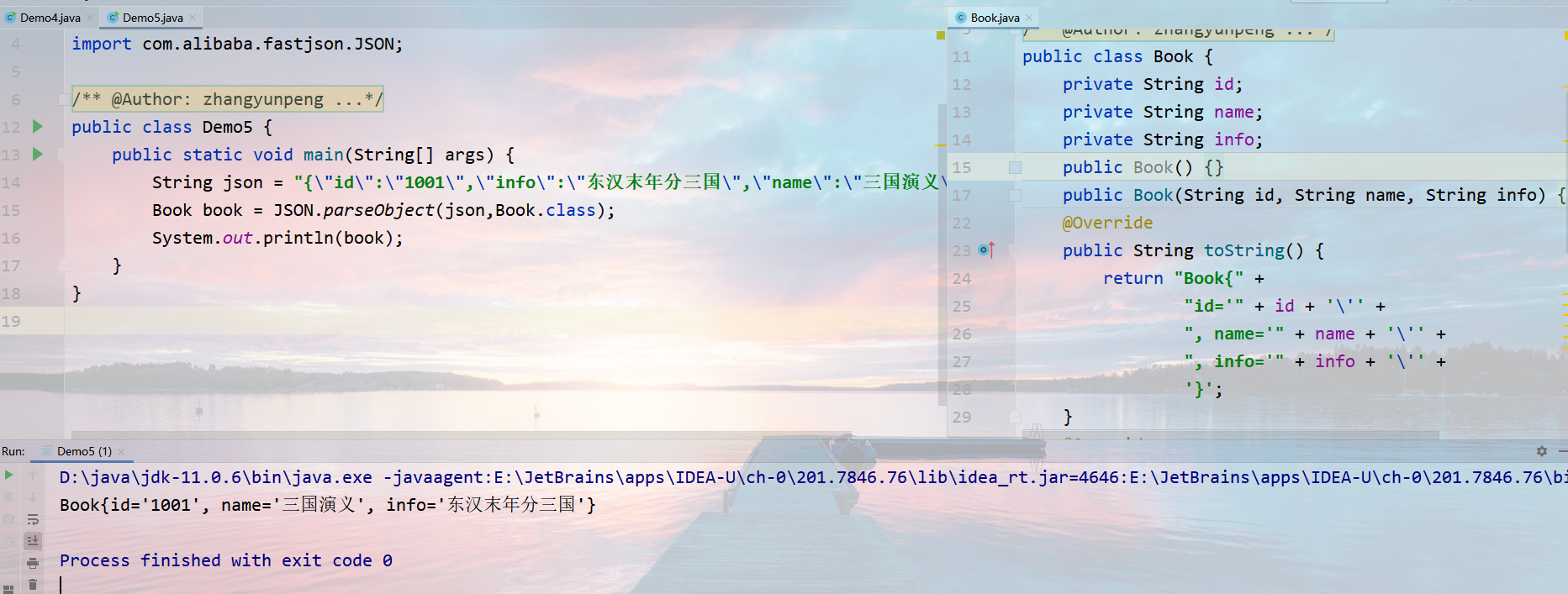
将JSON字符串转换为对象,在需要转换Java对象的位置, 编写如下代码:
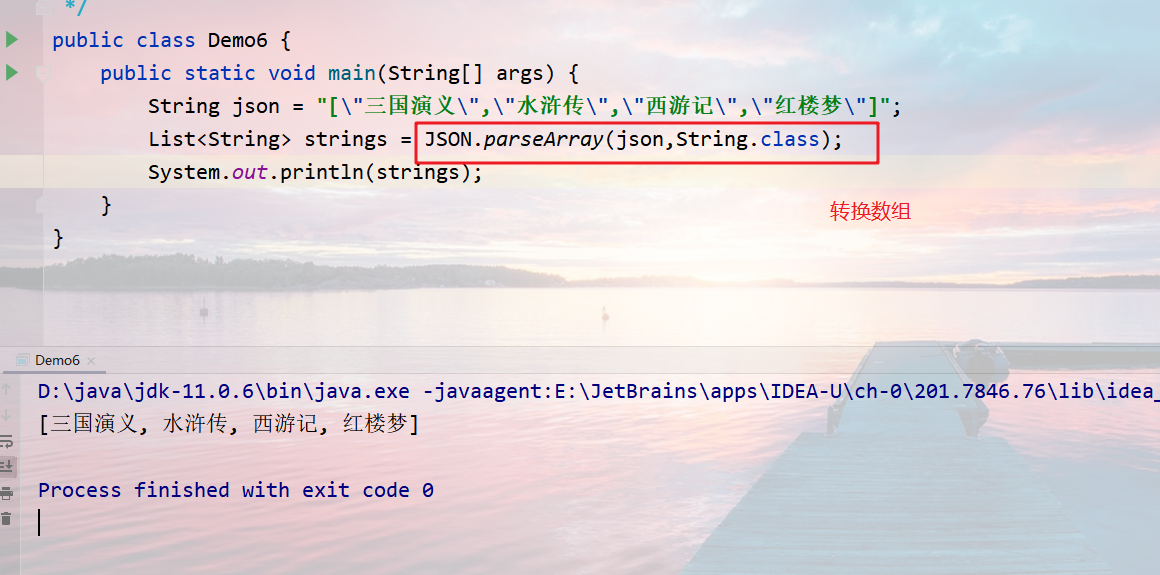
1 | 类型 对象名=JSON.parseObject(JSON字符串, 类型.class); |
 微信
微信 支付宝
支付宝


